
[ad_1]
L’optimisation des moteurs de recherche, dans son sens le plus élémentaire, repose sur une chose par-dessus tout : les robots des moteurs de recherche qui explorent et indexent votre site.
Mais presque tous les sites Web auront des pages que vous ne souhaitez pas inclure dans cette exploration.
Par exemple, voulez-vous vraiment que votre politique de confidentialité ou vos pages de recherche internes apparaissent dans les résultats Google ?
Dans le meilleur des cas, ceux-ci ne font rien pour générer activement du trafic vers votre site, et dans le pire des cas, ils pourraient détourner le trafic de pages plus importantes.
Heureusement, Google permet aux webmasters d’indiquer aux robots des moteurs de recherche quelles pages et quel contenu explorer et ce qu’il faut ignorer. Il existe plusieurs façons de procéder, la plus courante étant d’utiliser un fichier robots.txt ou la balise meta robots.
Nous avons une excellente explication détaillée des tenants et aboutissants de robots.txt, que vous devriez absolument lire.
Mais en termes généraux, il s’agit d’un fichier texte brut qui réside à la racine de votre site Web et suit le protocole d’exclusion des robots (REP).
Robots.txt fournit aux robots des instructions sur le site dans son ensemble, tandis que les balises méta robots incluent des instructions pour des pages spécifiques.
Certaines balises meta robots que vous pourriez utiliser incluent indicequi indique aux moteurs de recherche d’ajouter la page à leur index ; pas d’indexqui lui indique de ne pas ajouter de page à l’index ni de l’inclure dans les résultats de recherche ; suivrequi demande à un moteur de recherche de suivre les liens sur une page ; pas de suiviqui lui dit de ne pas suivre les liens, et une foule d’autres.
Les balises robots.txt et meta robots sont des outils utiles à conserver dans votre boîte à outils, mais il existe également un autre moyen d’indiquer aux robots des moteurs de recherche de ne pas indexer ou de ne pas suivre : X-Robots-Tag.
Qu’est-ce que le X-Robots-Tag ?
Le X-Robots-Tag est un autre moyen pour vous de contrôler la façon dont vos pages Web sont explorées et indexées par les araignées. Dans le cadre de la réponse d’en-tête HTTP à une URL, il contrôle l’indexation d’une page entière, ainsi que les éléments spécifiques de cette page.
Et tandis que l’utilisation des balises meta robots est assez simple, le X-Robots-Tag est un peu plus compliqué.
Mais ceci, bien sûr, soulève la question :
Quand utiliser le X-Robots-Tag ?
Selon Google, « Toute directive pouvant être utilisée dans une balise méta de robots peut également être spécifiée en tant que X-Robots-Tag. »
Bien que vous puissiez définir des directives liées à robots.txt dans les en-têtes d’une réponse HTTP avec à la fois la balise meta robots et la balise X-Robots, il existe certaines situations où vous voudriez utiliser la balise X-Robots – les deux plus courantes étant quand :
- Vous souhaitez contrôler la manière dont vos fichiers non HTML sont explorés et indexés.
- Vous souhaitez diffuser des directives à l’échelle du site plutôt qu’au niveau de la page.
Par exemple, si vous souhaitez empêcher l’exploration d’une image ou d’une vidéo spécifique, la méthode de réponse HTTP vous facilite la tâche.
L’en-tête X-Robots-Tag est également utile car il vous permet de combiner plusieurs balises dans une réponse HTTP ou d’utiliser une liste de directives séparées par des virgules pour spécifier des directives.
Peut-être que vous ne voulez pas qu’une certaine page soit mise en cache et qu’elle soit indisponible après une certaine date. Vous pouvez utiliser une combinaison de balises « noarchive » et « unavailable_after » pour demander aux robots des moteurs de recherche de suivre ces instructions.
Essentiellement, la puissance du X-Robots-Tag est qu’il est beaucoup plus flexible que le tag meta robots.
L’avantage d’utiliser un X-Robots-Tag avec les réponses HTTP est qu’il vous permet d’utiliser des expressions régulières pour exécuter des directives d’analyse sur des non-HTML, ainsi que d’appliquer des paramètres à un niveau global plus large.
Pour vous aider à comprendre la différence entre ces directives, il est utile de les classer par type. Autrement dit, s’agit-il de directives de robot ou de directives d’indexeur ?
Voici une feuille de triche pratique pour expliquer:
| Directives du robot d’exploration | Directives d’indexation |
| Robots.txt – utilise les directives user agent, allow, disallow et sitemap pour spécifier où les robots des moteurs de recherche sur site sont autorisés à explorer et non autorisés à explorer. | Balise Meta Robots – vous permet de spécifier et d’empêcher les moteurs de recherche d’afficher des pages particulières sur un site dans les résultats de recherche.
Pas de suivi – vous permet de spécifier des liens qui ne doivent pas transmettre d’autorité ou de PageRank. Tag X-Robots – vous permet de contrôler la façon dont les types de fichiers spécifiés sont indexés. |
Où placez-vous le X-Robots-Tag ?
Supposons que vous souhaitiez bloquer des types de fichiers spécifiques. Une approche idéale serait d’ajouter le X-Robots-Tag à une configuration Apache ou à un fichier .htaccess.
Le X-Robots-Tag peut être ajouté aux réponses HTTP d’un site dans une configuration de serveur Apache via le fichier .htaccess.
Exemples concrets et utilisations du X-Robots-Tag
Cela semble donc bien en théorie, mais à quoi cela ressemble-t-il dans le monde réel ? Nous allons jeter un coup d’oeil.
Disons que nous voulions que les moteurs de recherche n’indexent pas les types de fichiers .pdf. Cette configuration sur les serveurs Apache ressemblerait à ceci :
<Files ~ ".pdf$"> Header set X-Robots-Tag "noindex, nofollow" </Files>
Dans Nginx, cela ressemblerait à ceci :
location ~* .pdf$ add_header X-Robots-Tag "noindex, nofollow";
Maintenant, regardons un scénario différent. Disons que nous voulons utiliser le X-Robots-Tag pour bloquer l’indexation des fichiers image, tels que .jpg, .gif, .png, etc. Vous pouvez le faire avec un X-Robots-Tag qui ressemblerait à ce qui suit :
<Files ~ ".(png|jpe?g|gif)$"> Header set X-Robots-Tag "noindex" </Files>
Veuillez noter qu’il est crucial de comprendre le fonctionnement de ces directives et l’impact qu’elles ont les unes sur les autres.
Par exemple, que se passe-t-il si le X-Robots-Tag et une balise meta robots sont localisés lorsque les robots d’exploration découvrent une URL ?
Si cette URL est bloquée à partir de robots.txt, certaines directives d’indexation et de diffusion ne peuvent pas être découvertes et ne seront pas suivies.
Si des directives doivent être suivies, les URL contenant celles-ci ne peuvent pas être interdites d’exploration.
Rechercher une balise X-Robots
Il existe plusieurs méthodes différentes qui peuvent être utilisées pour rechercher un X-Robots-Tag sur le site.
Le moyen le plus simple de vérifier est d’installer une extension de navigateur qui vous indiquera les informations X-Robots-Tag sur l’URL.
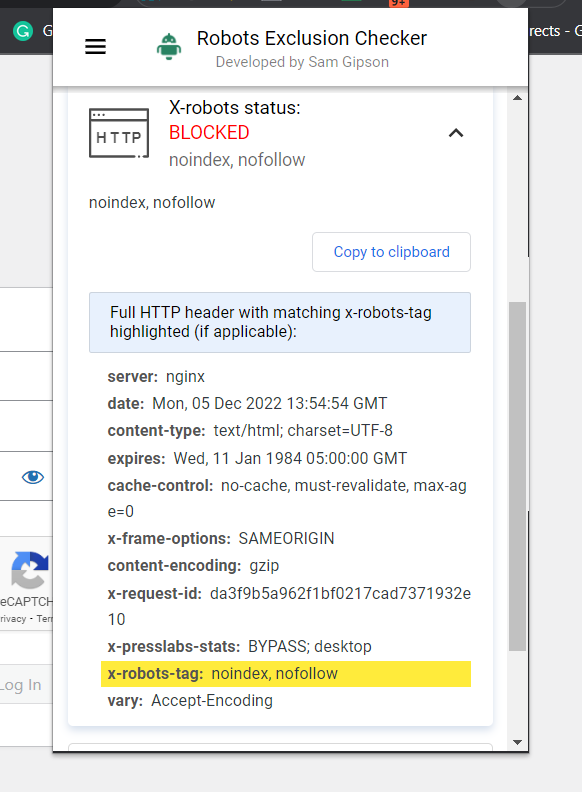
Un autre plugin que vous pouvez utiliser pour déterminer si un X-Robots-Tag est utilisé, par exemple, est le plugin Web Developer.
En cliquant sur le plug-in dans votre navigateur et en accédant à « Afficher les en-têtes de réponse », vous pouvez voir les différents en-têtes HTTP utilisés.

Une autre méthode qui peut être utilisée pour la mise à l’échelle afin d’identifier les problèmes sur les sites Web avec un million de pages est Screaming Frog.
Après avoir exécuté un site via Screaming Frog, vous pouvez accéder à la colonne « X-Robots-Tag ».
Cela vous montrera quelles sections du site utilisent la balise, ainsi que quelles directives spécifiques.
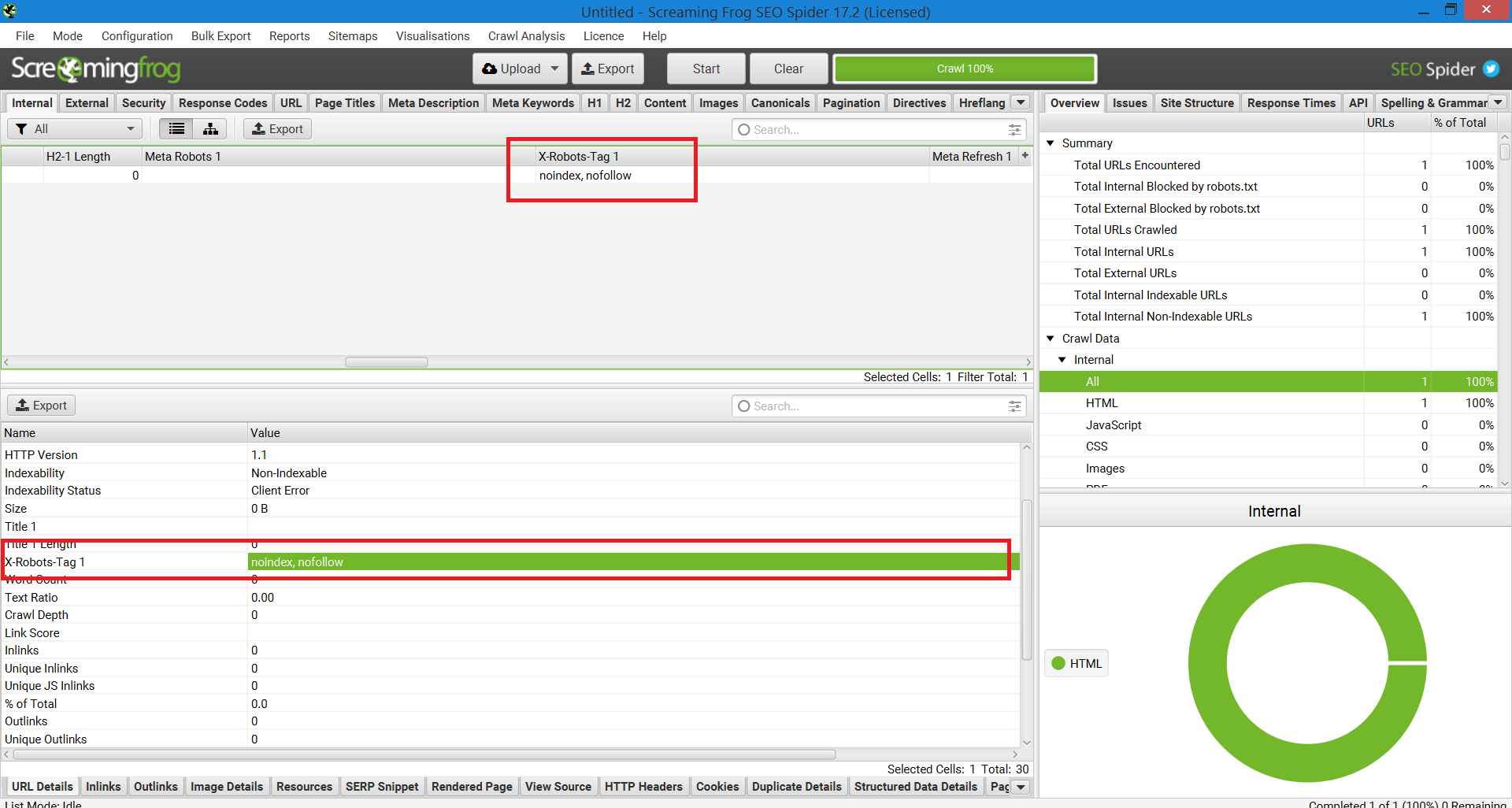 Capture d’écran du rapport Screaming Frog. X-Robot-Tag, décembre 2022
Capture d’écran du rapport Screaming Frog. X-Robot-Tag, décembre 2022Utiliser les X-Robots-Tags sur votre site
Comprendre et contrôler la façon dont les moteurs de recherche interagissent avec votre site Web est la pierre angulaire de l’optimisation des moteurs de recherche. Et le X-Robots-Tag est un outil puissant que vous pouvez utiliser pour faire exactement cela.
Soyez juste conscient : ce n’est pas sans danger. Il est très facile de se tromper et de désindexer tout votre site.
Cela dit, si vous lisez cet article, vous n’êtes probablement pas un débutant en référencement. Tant que vous l’utilisez à bon escient, prenez votre temps et vérifiez votre travail, vous trouverez que le X-Robots-Tag sera un complément utile à votre arsenal.
Plus de ressources:
Image en vedette : Song_about_summer/Shutterstock
[ad_2]
Source link -16