
Make this article seo compatible,Let there be subheadings for the article, be in french, create at least 700 words
La dernière décennie a marqué le passage du référencement des meilleures pratiques anecdotiques basées sur des feuilles de calcul à une approche davantage basée sur les données, comme en témoigne le plus grand nombre de professionnels du référencement apprenant Python.
À mesure que le nombre de mises à jour de Google augmente (11 en 2023), les professionnels du référencement reconnaissent la nécessité d’adopter une approche du référencement davantage basée sur les données, et les structures de liens internes pour les architectures de sites ne font pas exception.
Dans un article précédent, j’ai expliqué comment les liens internes pourraient être davantage axés sur les données, en fournissant du code Python sur la façon d’évaluer statistiquement l’architecture du site.
Au-delà de Python, la science des données peut aider les professionnels du référencement à découvrir plus efficacement des modèles cachés et des informations clés pour aider à signaler aux moteurs de recherche la priorité du contenu d’un site Web.
La science des données est l’intersection du codage, des mathématiques et des connaissances du domaine, le domaine, dans notre cas, étant le référencement.
Ainsi, même si les mathématiques et le codage (invariablement en Python) sont importants, le référencement n’est en aucun cas diminué dans son importance, car poser les bonnes questions sur les données et avoir le sentiment instinctif de savoir si les chiffres « semblent corrects » sont extrêmement importants.
Aligner l’architecture du site pour prendre en charge le contenu sous-lié
De nombreux sites sont construits comme un sapin de Noël, avec la page d’accueil tout en haut (étant la plus importante) et les autres pages par ordre décroissant d’importance dans les niveaux suivants.
Pour les scientifiques SEO parmi vous, vous voudrez savoir quelle est la distribution des liens selon différents points de vue. Cela peut être visualisé à l’aide du code Python de l’article précédent de plusieurs manières, notamment :
- Profondeur du site.
- Type de contenu.
- Classement de page interne.
- Valeur de conversion/revenu.
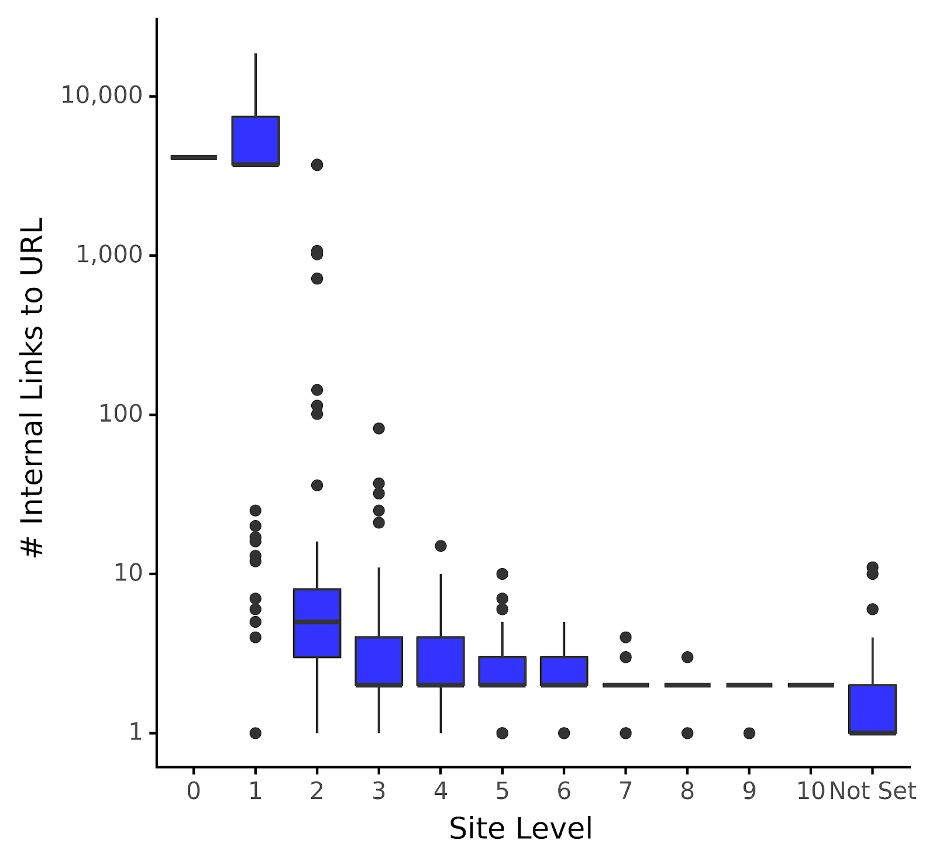
Le boxplot montre efficacement combien de liens sont « normaux » pour un site Web donné à différents niveaux du site. Les cases bleues représentent l’intervalle interquartile (c’est-à-dire les 25e et 75e quantiles) où se trouve la plupart (67 % pour être précis) du nombre de liens internes entrants.
Pensez à la courbe en cloche, mais au lieu de la regarder de côté (comme vous le feriez pour une montagne), vous la voyez comme un oiseau volant au-dessus de votre tête.
Par exemple, le graphique montre que pour les pages situées deux niveaux plus bas que la page d’accueil, la case bleue indique que 67 % des URL ont entre cinq et neuf liens internes entrants. Nous pouvons également constater que ce chiffre est considérablement (et peut-être sans surprise) bien inférieur aux pages situées à un saut de la page d’accueil.
La ligne épaisse qui coupe la case bleue est la médiane (50e quantile), représentant la valeur médiane. En reprenant l’exemple ci-dessus, les liens internes entrants médians sont de 7 pour les pages du niveau 2 du site, soit environ 5 000 fois moins que ceux du niveau 1 du site !
En passant, vous remarquerez peut-être que la ligne médiane n’est pas visible pour toutes les cases bleues, la raison étant que les données sont asymétriques (c’est-à-dire qu’elles ne sont pas normalement distribuées comme une courbe en forme de cloche).
Est-ce que c’est bon? Est-ce mauvais ? Les professionnels du référencement devraient-ils s’inquiéter ?
Un data scientist n’ayant aucune connaissance en SEO pourrait décider qu’il serait préférable de rétablir l’équilibre en travaillant sur la répartition des liens internes vers les pages par niveau de site.
À partir de là, toutes les pages qui se situent, disons, en dessous de la médiane ou du 20e percentile (quantile en science des données) pour leur niveau de site donné, un data scientist pourrait conclure que ces pages nécessitent davantage de liens internes.
En tant que tel, cela signifie souvent que les pages qui partagent le même nombre de sauts depuis la page d’accueil (c’est-à-dire le même niveau de profondeur du site) sont d’égale importance.
Cependant, du point de vue de la valeur de recherche, il est peu probable que cela soit vrai, surtout si l’on considère que certaines pages du même niveau ont simplement plus de demande de recherche que d’autres.
Ainsi, l’architecture du site doit donner la priorité aux pages avec plus de demande de recherche que celles avec moins de demande, quelle que soit leur place par défaut dans la hiérarchie – quel que soit leur niveau !
Révision du véritable classement des pages internes (TIPR)
Le True Internal Page Rank (TIPR), tel que popularisé par Kevin Indig, a adopté une approche beaucoup plus judicieuse en incorporant le PageRank externe, c’est-à-dire obtenu grâce aux backlinks. En termes mathématiques simples :
CONSEIL = Page Rank interne x autorité au niveau de la page des backlinks
Bien que ce qui précède soit la version non scientifique de sa métrique, il s’agit néanmoins d’une manière beaucoup plus utile et empirique de modéliser quelle est la valeur normale d’une page dans l’architecture d’un site Web. Si vous souhaitez que le code calcule cela, veuillez voir ici.
De plus, plutôt que d’appliquer cette métrique aux niveaux du site, il est bien plus instructif de l’appliquer par type de contenu. Pour un client de commerce électronique, nous voyons ci-dessous la répartition du TIPR par type de contenu :
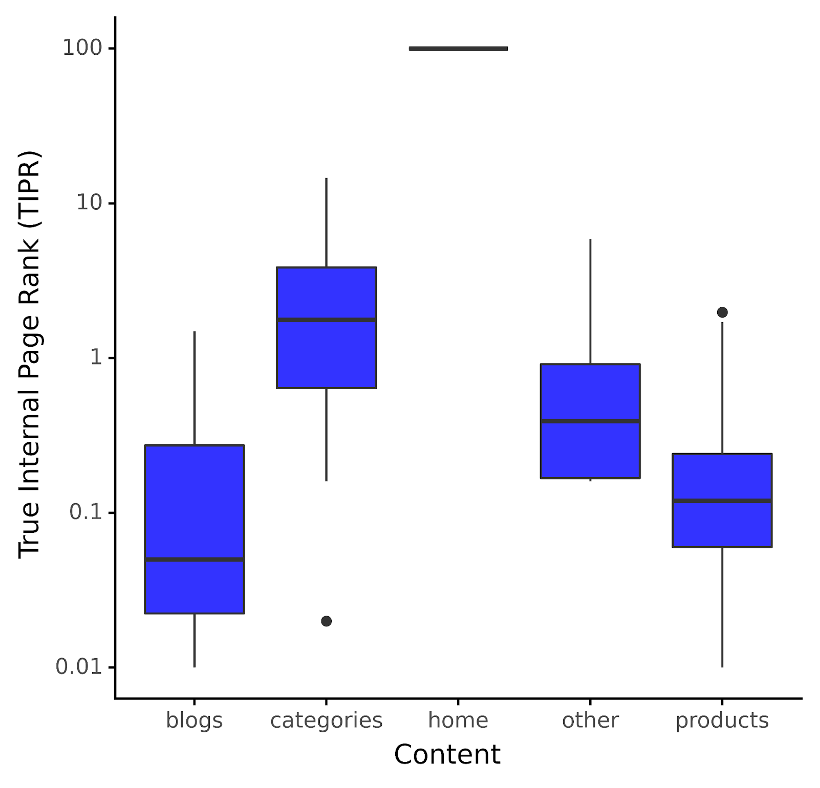 Image de l’auteur, décembre 2023
Image de l’auteur, décembre 2023L’intrigue dans le cas de cette boutique en ligne est que le TIPR médian pour le contenu des catégories ou les pages de liste de produits (PLP) est d’environ deux points TIPR.
Certes, TIPR est un peu abstrait, car comment cela se traduit-il par la quantité de liens internes requis ? Ce n’est pas le cas – du moins pas directement.
Malgré l’abstraction, il s’agit toujours d’une construction plus efficace pour façonner l’architecture du site.
Si vous vouliez voir quelles catégories étaient sous-performantes en termes de potentiel de classement, vous verriez simplement que les URL PLP étaient inférieures au 25e quantile et rechercheriez peut-être des liens internes provenant de pages ayant une valeur TIPR plus élevée.
Combien de liens et quel TIPR ? Avec un peu de modélisation, c’est une réponse pour un autre post.
Présentation du classement de page interne des revenus (RIPR)
L’autre question importante à laquelle il convient de répondre est la suivante : quel contenu mérite des positions plus élevées ?
Kevin a également préconisé une approche plus éclairée pour aligner les structures de liens internes sur les valeurs de conversion, que beaucoup d’entre vous appliquent déjà, espérons-le, à leurs clients ; Je dois être tout à fait d’accord.
Une solution simple et non scientifique consiste à prendre le rapport entre les revenus du commerce électronique et le TIPR, c’est-à-dire
RIPR = Revenus / TIPR
La métrique ci-dessus nous aide à voir à quoi ressemble le revenu normal par autorité de page, comme illustré ci-dessous :
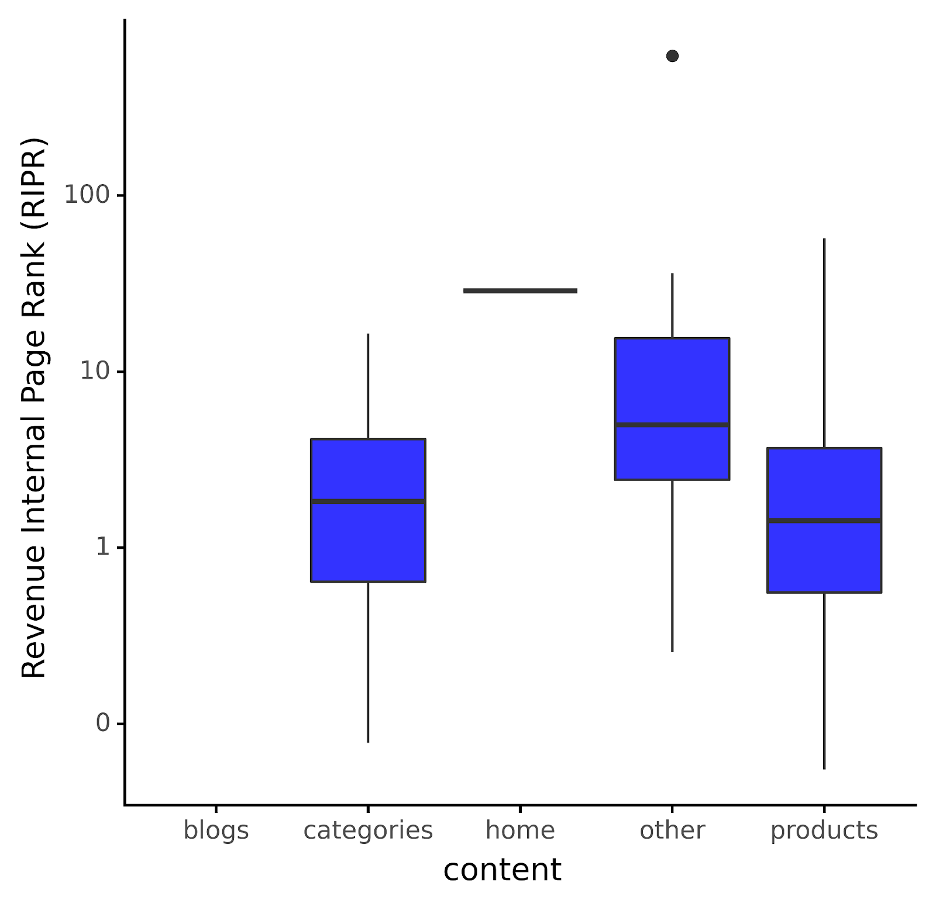 Image de l’auteur, décembre 2023
Image de l’auteur, décembre 2023Comme nous pouvons le constater, la situation change quelque peu ; du coup, nous ne voyons aucune case (c’est-à-dire la distribution) pour le contenu du blog car aucun revenu n’est enregistré pour ce contenu.
Applications pratiques? Si nous utilisons ceci comme modèle par type de contenu, toutes les pages supérieures au 75e quantile (c’est-à-dire au nord de leur boîte bleue) pour leur type de contenu respectif devraient avoir davantage de liens internes ajoutés.
Pourquoi? Parce qu’ils ont des revenus élevés mais ont une autorité de page très faible, ce qui signifie qu’ils ont un RIPR très élevé et devraient donc recevoir plus de liens internes pour le rapprocher de la médiane.
En revanche, ceux qui ont des revenus inférieurs mais trop de liens internes importants auront un RIPR inférieur et devraient donc se voir retirer des liens pour permettre aux moteurs de recherche d’accorder plus d’importance au contenu à revenus plus élevés.
Une mise en garde
RIPR intègre certaines hypothèses, telles que la configuration correcte du suivi des revenus analytiques afin que votre modèle constitue la base de recommandations efficaces en matière de liens internes.
Bien sûr, comme dans TIPR, il faut modéliser la valeur d’un lien interne en termes de valeur RIPR d’un lien interne à partir d’une page donnée.
C’est avant même d’arriver à l’emplacement du placement du lien interne lui-même.
Davantage de ressources:
Image en vedette : NicoElNino/Shutterstock