
Make this article seo compatible,Let there be subheadings for the article, be in french, create at least 700 words
Le nouveau pétrole n’est pas une donnée ou une attention. Ce sont des mots. Le différenciateur pour créer des modèles d’IA de nouvelle génération est l’accès au contenu lors de la normalisation de la puissance de calcul, du stockage et de l’énergie.
Mais le Web devient déjà trop petit pour assouvir la soif de nouveaux modèles.
Certains dirigeants et chercheurs affirment que les besoins de l’industrie en données textuelles de haute qualité pourraient dépasser l’offre d’ici deux ans, ce qui pourrait ralentir le développement de l’IA.
Même un réglage fin ne semble pas fonctionner aussi bien que la simple construction de modèles plus puissants. Une étude de cas de recherche Microsoft montre que les invites efficaces peuvent surpasser de 27 % un modèle affiné.
Nous nous demandions si l’avenir serait constitué de nombreux petits modèles perfectionnés ou de quelques grands modèles globaux. Il semble que ce soit le dernier cas.
Il n’y a pas de stratégie d’IA sans stratégie de données.
Avides de contenu de plus haute qualité pour développer la prochaine génération de grands modèles de langage (LLM), les développeurs de modèles commencent à payer pour du contenu naturel et relancent leurs efforts pour étiqueter les données synthétiques.
Pour les créateurs de contenu de tout type, ce nouveau flux d’argent pourrait ouvrir la voie à un nouveau modèle de monétisation de contenu qui encourage la qualité et améliore le Web.
Améliorez vos compétences grâce aux informations hebdomadaires d’experts de Growth Memo. Abonnez-vous gratuitement !
KYC : IA
Si le contenu est le nouveau pétrole, les réseaux sociaux sont des plateformes pétrolières. Google a investi 60 millions de dollars par an dans l’utilisation du contenu Reddit pour entraîner ses modèles et faire apparaître les réponses Reddit en haut de la recherche. Des centimes, si vous me demandez.
Le PDG de YouTube, Neal Mohan, a récemment envoyé un message clair à OpenAI et à d’autres développeurs de modèles selon lequel la formation sur YouTube est interdite, pour défendre les énormes réserves de pétrole de l’entreprise.
Le New York Times, qui mène actuellement une action en justice contre OpenAI, a publié un article indiquant qu’OpenAI a développé Whisper pour former des modèles sur les transcriptions YouTube, et que Google utilise le contenu de toutes ses plates-formes, comme les critiques de Google Docs et Maps, pour former son IA. des modèles.
Les fournisseurs de données d’IA générative comme Appen ou Scale AI recrutent des rédacteurs (humains) pour créer du contenu pour la formation des modèles LLM.
Ne vous y trompez pas, les écrivains ne s’enrichissent pas en écrivant pour l’IA.
Pour 25 à 50 dollars de l’heure, les rédacteurs effectuent des tâches telles que le classement des réponses de l’IA, la rédaction d’histoires courtes et la vérification des faits.
Les candidats doivent être titulaires d’un doctorat. ou une maîtrise ou fréquentent actuellement un collège. Les fournisseurs de données recherchent clairement des experts et de « bons » rédacteurs. Mais les premiers signes sont prometteurs : écrire pour l’IA pourrait être monétisable.
 Crédit image : Kevin Indig
Crédit image : Kevin Indig Crédit image : Kevin Indig
Crédit image : Kevin IndigLes développeurs de modèles recherchent du bon contenu dans tous les coins du Web, et certains sont heureux de le vendre.
Les plateformes de contenu comme Photobucket vendent des photos entre cinq cents et un dollar pièce. Les vidéos courtes peuvent coûter entre 2 $ et 4 $ ; les films plus longs coûtent entre 100 et 300 dollars par heure de séquence.
Avec des milliards de photos, l’entreprise a découvert du pétrole dans son jardin. Quel PDG peut résister à une telle tentation, d’autant plus que la monétisation des contenus devient de plus en plus difficile ?
À partir du contenu gratuit :
Les éditeurs sont pressés de plusieurs côtés :
- Rares sont ceux qui sont préparés à la mort des cookies tiers.
- Les réseaux sociaux envoient moins de trafic (Meta) ou se détériorent en qualité (X).
- La plupart des jeunes reçoivent des nouvelles de TikTok.
- La SGE se profile à l’horizon.
Ironiquement, un meilleur étiquetage du contenu de l’IA pourrait aider au développement du LLM, car il est plus facile de séparer le contenu naturel du contenu synthétique.
En ce sens, il est dans l’intérêt des développeurs LLM d’étiqueter le contenu de l’IA afin de pouvoir l’exclure de la formation ou l’utiliser correctement.
Étiquetage
Rechercher des mots pour former des LLM n’est qu’un aspect du développement de modèles d’IA de nouvelle génération. L’autre est l’étiquetage. Les développeurs de modèles ont besoin d’un étiquetage pour éviter l’effondrement du modèle, et la société en a besoin comme bouclier contre les fausses nouvelles.
Un nouveau mouvement d’étiquetage de l’IA se développe malgré l’abandon du filigrane par OpenAI en raison d’une faible précision (26 %). Au lieu d’étiqueter eux-mêmes le contenu, ce qui semble futile, les grandes technologies (Google, YouTube, Meta et TikTok) poussent les utilisateurs à étiqueter le contenu de l’IA avec une approche carotte/bâton.
Google utilise une approche à deux volets pour lutter contre le spam de l’IA dans les recherches : mettre en évidence les forums comme Reddit, où le contenu est très probablement créé par des humains, et imposer des sanctions.
De AIffificience :
Google fait apparaître davantage de contenu provenant des forums dans les SERP pour contrebalancer le contenu de l’IA. La vérification est le filigrane IA ultime. Même si Reddit ne peut pas empêcher les humains d’utiliser l’IA pour créer des publications ou des commentaires, les chances sont moindres en raison de deux choses que la recherche Google n’a pas : la modération et le karma.
Oui, les Content Goblins ont déjà visé Reddit, mais la plupart des 73 millions d’utilisateurs actifs quotidiens fournissent des réponses utiles.1 Les modérateurs de contenu punissent le spam par des interdictions, voire des expulsions. Mais le facteur de qualité le plus puissant sur Reddit est Karma, « le score de réputation d’un utilisateur qui reflète ses contributions à la communauté ». Grâce à de simples votes positifs ou négatifs, les utilisateurs peuvent gagner en autorité et en fiabilité, deux ingrédients essentiels des systèmes qualité de Google.
Google a récemment précisé qu’il s’attend à ce que les commerçants ne suppriment pas les métadonnées d’IA des images à l’aide du protocole de métadonnées IPTC.
Lorsqu’une image comporte une balise telle que compositeSynthetic, Google peut la qualifier de « générée par l’IA » n’importe où, pas seulement dans les magasins. La punition pour la suppression des métadonnées de l’IA n’est pas claire, mais je l’imagine comme une pénalité de lien.
IPTC est le même format que Meta utilise pour Instagram, Facebook et WhatsApp. Les deux sociétés attribuent des balises méta IPTC à tout contenu provenant de leurs propres LLM. Plus les fabricants d’outils d’IA suivent les mêmes directives pour marquer et étiqueter le contenu d’IA, plus les systèmes de détection fonctionnent de manière fiable.
Lorsque des images photoréalistes sont créées à l’aide de notre fonctionnalité Meta AI, nous faisons plusieurs choses pour nous assurer que les gens savent que l’IA est impliquée, notamment en plaçant des marqueurs visibles que vous pouvez voir sur les images, ainsi que des filigranes invisibles et des métadonnées intégrées dans les fichiers image. Utiliser ainsi à la fois le filigrane invisible et les métadonnées améliore à la fois la robustesse de ces marqueurs invisibles et aide d’autres plateformes à les identifier.
Les inconvénients du contenu de l’IA sont minimes lorsque le contenu ressemble à de l’IA. Mais lorsque le contenu de l’IA semble réel, nous avons besoin d’étiquettes.
Alors que les annonceurs tentent de s’éloigner du look IA, les plateformes de contenu le préfèrent car il est facile à reconnaître.
Pour les artistes commerciaux et les annonceurs, l’IA générative a le pouvoir d’accélérer considérablement le processus créatif et de diffuser des publicités personnalisées aux clients à grande échelle – une sorte de Saint Graal dans le monde du marketing. Mais il y a un hic : de nombreuses images que les modèles d’IA génèrent présentent une douceur caricaturale, des défauts révélateurs, ou les deux.
Les consommateurs se retournent déjà contre « l’apparence de l’IA », à tel point qu’une étrange et cinématographique publicité du Super Bowl pour l’association caritative chrétienne He Gets Us a été accusée d’être née de l’IA – même si c’est un photographe qui a créé ses images.
YouTube a commencé à appliquer de nouvelles directives pour les créateurs de vidéos, selon lesquelles le contenu réaliste de l’IA doit être étiqueté.
Les défis posés par l’IA générative sont un domaine d’intérêt constant pour YouTube, mais nous savons que l’IA introduit de nouveaux risques que de mauvais acteurs peuvent tenter d’exploiter lors d’une élection. L’IA peut être utilisée pour générer du contenu susceptible d’induire les spectateurs en erreur, en particulier s’ils ignorent que la vidéo a été modifiée ou créée de manière synthétique. Pour mieux répondre à ce problème et informer les téléspectateurs lorsque le contenu qu’ils regardent est modifié ou synthétique, nous commencerons à introduire les mises à jour suivantes :
- Divulgation du créateur : Les créateurs seront tenus de divulguer s’ils ont créé du contenu modifié ou synthétique qui est réaliste, y compris à l’aide d’outils d’IA. Cela inclura le contenu électoral.
- Étiquetage : Nous étiqueterons les contenus électoraux modifiés ou synthétiques réalistes qui ne violent pas nos règles, afin d’indiquer clairement aux téléspectateurs qu’une partie du contenu a été modifiée ou synthétique. Lors des élections, ce libellé sera affiché à la fois dans le lecteur vidéo et dans la description de la vidéo, et apparaîtra quels que soient le créateur, les points de vue politiques ou la langue.
La plus grande crainte imminente concerne les faux contenus d’IA qui pourraient influencer l’élection présidentielle américaine de 2024.
Aucune plateforme ne veut être le Facebook de 2016, qui a connu des dommages durables à sa réputation qui ont eu un impact sur le cours de ses actions.
Les acteurs étatiques chinois et russes ont déjà expérimenté de fausses informations sur l’IA et tenté de s’immiscer dans les élections taïwanaises et américaines à venir.
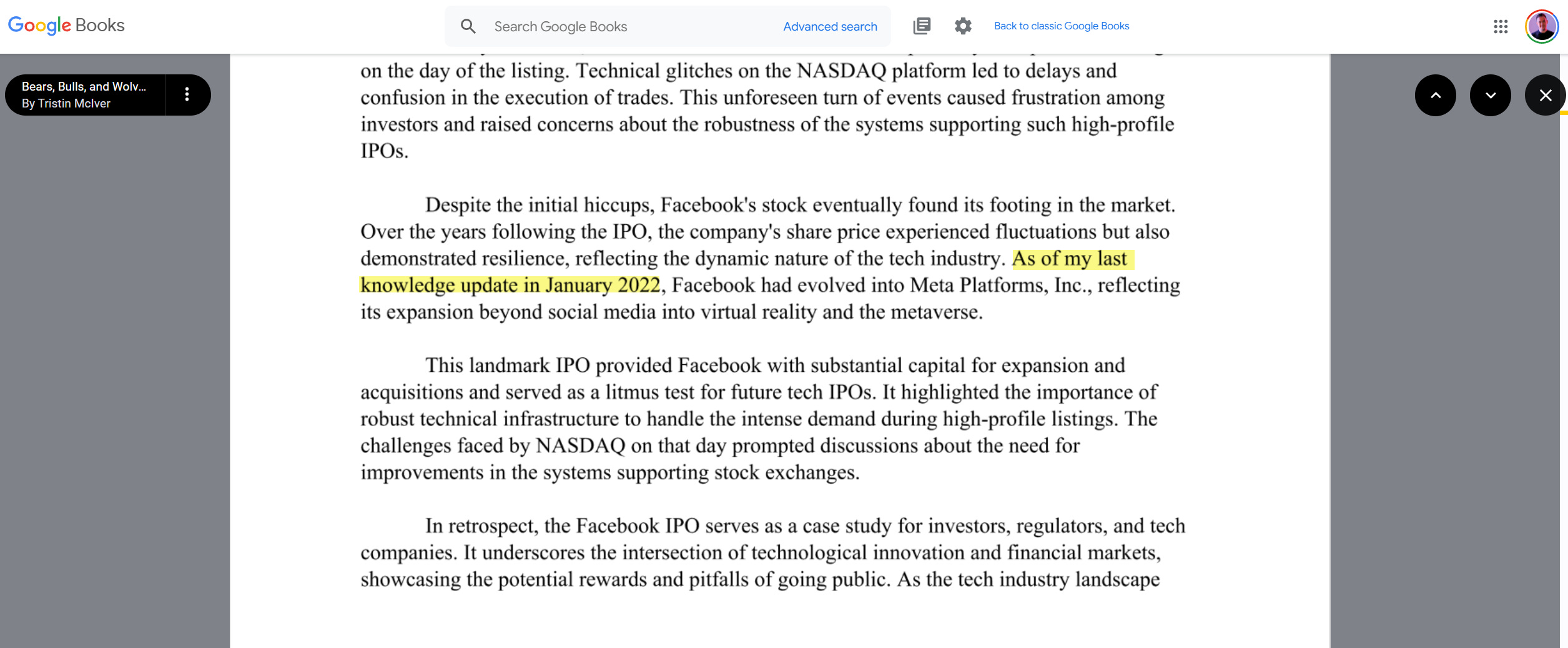
Maintenant qu’OpenAI est sur le point de publier Sora, qui crée des vidéos hyperréalistes à partir d’invites, il n’est pas loin d’imaginer comment les vidéos d’IA peuvent causer des problèmes sans étiquetage strict. La situation est difficile à maîtriser. Google Livres propose déjà des livres clairement écrits avec ou par ChatGPT.
 Crédit image : Kevin Indig
Crédit image : Kevin IndigEmporter
Les étiquettes, qu’elles soient mentales ou visuelles, influencent nos décisions. Ils annotent le monde à notre place et ont le pouvoir de créer ou de détruire la confiance. À l’instar de l’heuristique des catégories dans les achats, les étiquettes simplifient notre prise de décision et le filtrage des informations.
Du milieu désordonné :
Enfin, l’idée d’heuristiques de catégories, de chiffres sur lesquels les clients se concentrent pour simplifier la prise de décision, comme les mégapixels pour les caméras, offre une voie pour spécifier l’optimisation du comportement des utilisateurs. Un magasin de commerce électronique vendant des caméras, par exemple, devrait optimiser ses fiches produits pour hiérarchiser visuellement les heuristiques des catégories. Certes, vous devez d’abord comprendre les heuristiques de vos catégories, et elles peuvent varier en fonction du produit que vous vendez. Je suppose que c’est ce qu’il faut pour réussir en référencement de nos jours.
Bientôt, les étiquettes nous diront quand le contenu est écrit par l’IA ou non. Dans une enquête publique menée auprès de 23 000 personnes interrogées, Meta a constaté que 82 % des personnes souhaitaient des étiquettes sur le contenu de l’IA. Il reste à voir si les normes communes et les sanctions fonctionnent, mais l’urgence est là.
Il y a aussi une opportunité ici : les labels pourraient mettre en lumière les écrivains humains et rendre leur contenu plus précieux, en fonction de la qualité du contenu de l’IA.
De plus, écrire pour l’IA pourrait être un autre moyen de monétiser le contenu. Même si les taux horaires actuels ne rendent personne riche, la formation de modèles ajoute une nouvelle valeur au contenu. Les plateformes de contenu pourraient trouver de nouvelles sources de revenus.
Le contenu Web est devenu extrêmement commercialisé, mais les licences d’IA pourraient inciter les écrivains à créer à nouveau du bon contenu et à se libérer des revenus d’affiliation ou publicitaires.
Parfois, le contraste rend la valeur visible. Peut-être que l’IA peut finalement améliorer le Web.
Pour les entreprises d’IA gourmandes en données, Internet est trop petit
Le pouvoir de l’incitation
Dans la course clandestine des Big Tech pour acheter des données de formation en IA
OpenAI abandonne l’outil de détection pour le texte généré par l’IA
Métadonnées des photos IPTC
Étiquetage des images générées par l’IA sur Facebook, Instagram et Threads
Comment l’industrie publicitaire fait en sorte que les images de l’IA ressemblent moins à l’IA
Comment nous aidons les créateurs à divulguer du contenu modifié ou synthétique
Lutter contre la désinformation électorale générée par l’IA
La Chine cible les électeurs américains et taïwanais avec une désinformation alimentée par l’IA
Google Books indexe les déchets générés par l’IA
Notre approche de l’étiquetage du contenu généré par l’IA et des médias manipulés
Image en vedette : Paulo Bobita/Search Engine Journal