
[ad_1]
Le département IA de la société mère de Facebook Meta a présenté un nouveau grand modèle de langage qui a été principalement formé sur un corpus de littérature de recherche scientifique (naturelle) telle que des articles spécialisés, des notes de cours, des résumés et des critiques. Selon la carte modèle, le groupe cible principal est constitué de scientifiques et d’étudiants. Galactica AI, comme on l’appelle, se décline en cinq tailles allant de 120 millions à 120 milliards de paramètres. Il est apparemment open source (avec la mise en garde : il y a quelques incohérences avec cette déclaration, plus à ce sujet ci-dessous).
Sur GitHub, c’est dans un dépôt appelé galai par l’équipe Papers with Code. Selon le site Web, le modèle provient de cette équipe et Meta fournit ou a fourni les ressources matérielles nécessaires. Au total, 48 millions de documents de recherche ont été intégrés au modèle, à partir desquels 88 milliards de jetons ont été générés. Au total, l’équipe Meta-AI, composée de neuf personnes, a utilisé 106 milliards de jetons, qu’elle a générés à partir de manuels, d’articles et de bases de connaissances accessibles au public, et pour lesquels elle fournit une interface en langage naturel avec Galactica. De plus amples informations sur les sources peuvent être trouvées dans le document de recherche de l’équipe, qui contient un résumé ainsi qu’un index annoté.
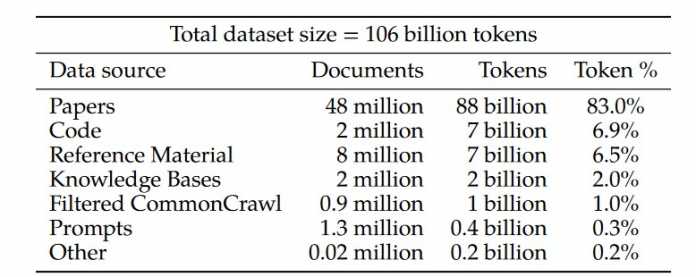
Corpus Galactica de la littérature de recherche – une version entièrement annotée est disponible à la fin de l’article.
(Image : Équipe Meta AI)
Selon ses éditeurs, Galactica peut prédire les citations, générer du LaTeX, raisonner, créer des documents, générer des molécules et générer des annotations de protéines. Un petit exemple est disponible sur GitHub, des exemples de démonstrations plus détaillés peuvent être trouvés sur le site Web du projet associé galactica.org. Le site Web présente des revues de littérature générées avec le modèle, des entrées de Wikipédia, des notes de cours et des réponses générées par la machine à des questions techniques en tant qu’applications possibles.


Aperçu des capacités du modèle d’IA Galactica formé sur la littérature scientifique.
(Image : Galactica.org)
Le modèle open-source, qui compte jusqu’à 120 milliards de paramètres, serait particulièrement performant dans les tâches des matières MINT (« STEM », c’est-à-dire les mathématiques, l’informatique, les sciences naturelles et la technologie/sciences de l’ingénieur), mais a beaucoup moins de succès. données en formation utilisées comme BLOOM par Huggingface et les Open Pre-Trained Transformer Models (OPT) par Meta.
Open Model 1.0 : Gratuit ou payant, sous quelle licence ?
Les éditeurs ne savent toujours pas très bien sous quelle licence se trouve le modèle, car deux spécifications de licence apparemment contradictoires sont stockées dans le référentiel. Si vous appuyez sur le bouton Licence lié ou ouvrez le répertoire Licence, la licence mentionnée est initialement Apache 2.0, ce qui rendrait le modèle open source et, selon la liste de contrôle qui y est présentée, librement disponible « pour un usage commercial, la modification, le partage, l’utilisation dans Domaine des brevets et usage privé ». Il est soumis à trois restrictions : aucun droit de marque ne peut en être dérivé, la responsabilité est limitée et les auteurs du modèle ne fournissent aucune garantie.
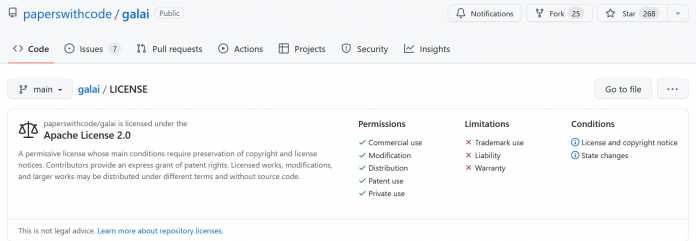
La première des deux licences spécifiées dans le référentiel Galactica AI accorde également une utilisation commerciale – qui à son tour exclut la licence « Creative Commons Attribution – NonCommercial 4.0 » qui est également stockée. Les éditeurs osent douter que l’utilisation dans le domaine des brevets soit sécurisée.
(Image : Documents avec code)
Certaines de ces informations contredisent un autre fichier nommé License-Model.md stocké dans le référentiel ou sont au moins partiellement restreintes par celui-ci : La licence Creative Commons Attribution NonCommercial 4.0 exclut explicitement l’utilisation commerciale. Selon l’éditeur « Papers with Code », il s’agit d’un modèle ouvert et open source :
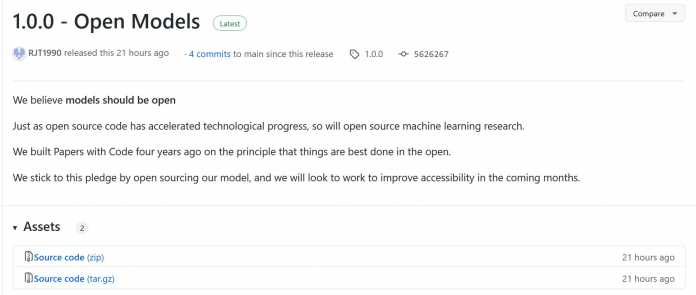
Texte d’information Open Models 1.0, du référentiel Papers with Code sur Github, sur le modèle de langage d’IA à grande échelle Galactica AI de Meta
Attention : Celui qui utilise l’outil de recherche peut céder des droits sur le contenu
L’open source est une épée à double tranchant, comme on l’apprend au plus tard en parcourant les conditions d’utilisation sur le site Web de Galactica, qui sont en petits caractères. Les utilisateurs de l’outil de recherche soutenu par l’IA de « Papers with Code » et Meta peuvent accorder au groupe le droit de visualiser, de vérifier et, si nécessaire, d’exploiter tout le contenu de l’utilisateur (les zones ne sont pas très clairement délimitées). Les termes commerciaux et non commerciaux sont également quelque peu confondus dans les conditions d’utilisation. Bien que le site Web soit destiné à un usage non commercial et informatif uniquement, les documents Galactica qui y sont présentés sont sous licence Creative Commons Attribution-ShareAlike 4.0 International (CC BY-SA 4.0), qui s’applique également aux documents publiés à des fins commerciales ( » y compris à des fins commerciales »).
Apparemment, il est conseillé de consulter d’abord un avocat spécialisé afin de clarifier vos propres objectifs avant d’utiliser l’API ou de commencer allègrement avec le forking. Toute personne qui utilise le site Web a automatiquement accepté les conditions qui y sont ancrées, qui peuvent être lues en détail ici. Avec l’utilisation, entre autres, son propre employeur devient responsable envers Meta en cas d’utilisation abusive, et certains groupes sont exclus de l’utilisation. Par exemple, être majeur est une exigence et un casier judiciaire antérieur (qui n’est pas précisé) pourrait empêcher l’utilisation de l’outil.
Selon l’accord, les utilisateurs eux-mêmes sont responsables des textes, photos, codes, vidéos et autres entrées que les utilisateurs saisissent sur la plate-forme, notamment en s’assurant que le contenu ne les rend pas personnellement identifiables. Cela devrait être pertinent dans la mesure où Meta et l’équipe PoC peuvent rester ouverts à l’utilisation ultérieure de l’entrée pour former leur modèle. Cependant, cela n’est pas très clair d’après les informations sur le site Web, car Meta indique également que la propriété et le droit d’auteur (de la sortie générée) appartiennent aux utilisateurs. On ne sait toujours pas comment les utilisateurs peuvent également protéger leur droit d’auteur sans divulguer de données personnelles, d’autant plus qu’il est apparemment également nécessaire de s’inscrire sur le site Web pour l’utiliser. Le site Web spécifie également les comportements indésirables et interdits lors de l’utilisation de l’outil, y compris la violation des droits d’auteur d’autrui. Les détails peuvent être trouvés dans les conditions d’utilisation sous « Utilisation interdite ».
Avertissement concernant la sortie de texte alambiqué
Sous les exemples fournis sur le site Web, et avant de procéder à la génération de votre propre texte, se trouve un avertissement indiquant que la sortie fournie peut ne pas être fiable et que le modèle est sujet aux hallucinations (« ATTENTION : les sorties peuvent ne pas être fiables ! Les modèles de langage sont sujets aux hallucinations text »), les données d’entraînement reflètent un état jusqu’en juillet 2022. La vérification de la plausibilité, de la validité, de la véracité et de l’exactitude des textes générés par l’IA relève donc toujours de la responsabilité de l’utilisateur humain.
Cependant, il peut être difficile pour les lecteurs inexpérimentés ou les lecteurs qui ne connaissent pas le sujet de faire la distinction entre ce qui est vrai et ce qui est faux, car les produits répondent formellement aux exigences des produits textuels scientifiques et le style et la langue font autorité. En particulier, la fonction de création d’articles Wikipédia à consonance scientifique, parfois agrémentés de formules mathématiques, sur simple pression d’un bouton pourrait ouvrir la porte à des campagnes de désinformation.
Voix critiques sur l’outil du patron de Meta-AI
Le critique de Yann LeCun Gary Marcus et les chercheurs qui l’entourent l’ont déjà vivement critiqué dans un article de Substack intitulé « A Few Words About Bullshit ». Le résultat de l’outil est un mélange brut de bonnes idées solides et de folie. Le neuroscientifique new-yorkais Marcus trouve le mélange de mathématiques et de science confabulées particulièrement discutable, voire carrément dangereux, et met en garde contre les absurdités fabriquées. Son collègue David Chapman a compilé quelques exemples dans un fil Twitter.
Quiconque est plus intéressé par les bases du modèle et ses utilisations possibles peut lire l’article scientifique sur Galactica, dans lequel l’équipe de recherche de neuf personnes de Meta AI décrit les données et les matériaux inclus et les méthodes avec lesquelles le modèle a été formé. La carte du modèle et d’autres ressources sont stockées sur GitHub, le modèle a déjà été fork trente fois en 22 heures.
(son)
[ad_2]
Source link -55